.png)

前回のブログでは、非構造化データをマクロとミクロの2つグラフ構造で定義することについてお伝えしました。その中で、マクロレベルはデータの種類を表す「クラス」とその関係を表す「プロパティ」、ミクロレベルは特定の1つのものや文字列などのデータ表す「主語」「目的語」とその関係を表す「述語」を要素としていました。またマクロレベルのクラスは階層的に定義できるとお伝えしました。
半構造化データに関するブログ
① 半構造化データとは何か?
https://jp.drinet.co.jp/blog/datamanagement/semi-structured-data
② マクロとミクロ:2つのレベルで半構造化データを定義する
https://jp.drinet.co.jp/blog/datamanagement/qcfixpdzmf
③ 半構造化データのマクロレベルとミクロレベルの関連と注意点の考察 ~非構造化データの意味を定義する~
本ブログ
今回のブログでは、EDW(Enterprise Data World)でこれら2つのグラフ構造の関係がどう語られていたのかをお伝えします。
ミクロレベルのデータ(主語、目的語)を同種のグループでまとめるとマクロレベルのクラスになります。この時、データを適したクラスに所属させることで、そのデータが持つ意味を定義できます。また1つのデータを複数のクラスに所属させることで、データの意味をより論理的かつ正確に定義することができます。(図1)
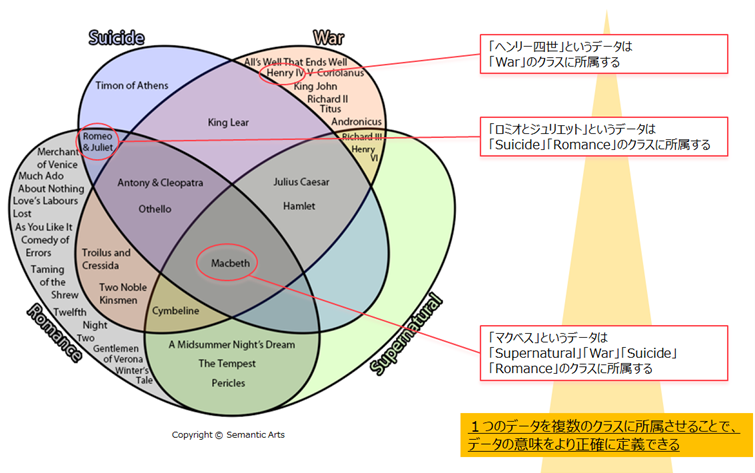
- 図1 -
データを複数のクラスに所属させることもできますし、どのクラスにも所属させないこともできます。ただしデータがどのクラスにも所属しない場合、そのデータの意味が理解できなくなってしまいます。そのため全てのデータを極力いずれかのクラスに所属させることが望ましいです。またデータが所属するクラスはそのデータの発生時に決まるのではなく、後追いで定義することも可能です。そのためグラフ構造の定義段階ではクラスのメンバーとなるデータは決まっておらず、データの発生後に順次メンバーがクラスに追加されていくことになります。
先述の通り、1つのデータを複数のクラスに所属させることができます。ではいくつのクラスに所属させれば、つまりデータに対する「意味」をどれだけ管理すれば十分なのでしょうか?
この問いに対する明確な答えはありません。非構造化データの意味を管理するために重要なことは、以下3点となります。
- 非構造化データを用いて実現したいことに応じた定義をすること
- データを使い始める前に全ての設計が完了していなくてもいいと認識すること
- それまでの作業を混乱させることなく新しい意味をネットワークとデータの両方に随時追加できること
半構造化データの参考情報
ブログ「半構造化データとは何か?」
半構造化データとは?構造化データ、非構造化データとの違いを解説します。
https://jp.drinet.co.jp/blog/datamanagement/semi-structured-data
ブログ「マクロとミクロ:2つのレベルで半構造化データを定義する」
半構造化データの定義についてお伝えします。
https://jp.drinet.co.jp/blog/datamanagement/qcfixpdzmf
15,000人以上の受講実績!
データマネジメントに欠かせないコアスキル
「データモデリング」を学べます!

データモデリング初心者が学ぶべき全ての知識を効率的に習得!実務に近い感覚で概念データモデリングの演習を行えます。研修期間中は、マンツーマンによる2回のオンライン講習と、3つの学習課題に取り組んでいただきます。





