.png)

半構造化データとは?構造化データ、非構造化データとの違いを解説
EDW(Enterprise Data World)では半構造化データをどう管理・活用するかが多く語られていました。それらのトピックも今後触れていきたいと思いますが、本ブログではその前段として『半構造化データとは何か?』をテーマにお伝えします。
『半構造化データ』とはどんなもので、構造化データや非構造化データとは何が違うのでしょうか?
半構造化データに関するブログ
① 半構造化データとは何か?
本ブログ
② マクロとミクロ:2つのレベルで半構造化データを定義する
https://jp.drinet.co.jp/blog/datamanagement/qcfixpdzmf
③ 半構造化データのマクロレベルとミクロレベルの関連と注意点の考察 ~非構造化データの意味を定義する~
https://jp.drinet.co.jp/blog/datamanagement/4d0z9nnj60
構造化データとは?
まず構造化データ(Structured Data)の特徴を挙げてみます。構造化データはあらかじめデータを管理する構造を決めて、その構造に合わせてデータを格納していく「Schema-on-Write」の方式を取ります。各企業など、特定のスコープ内のデータを管理するために用いられ、RDBMSで実装されます。
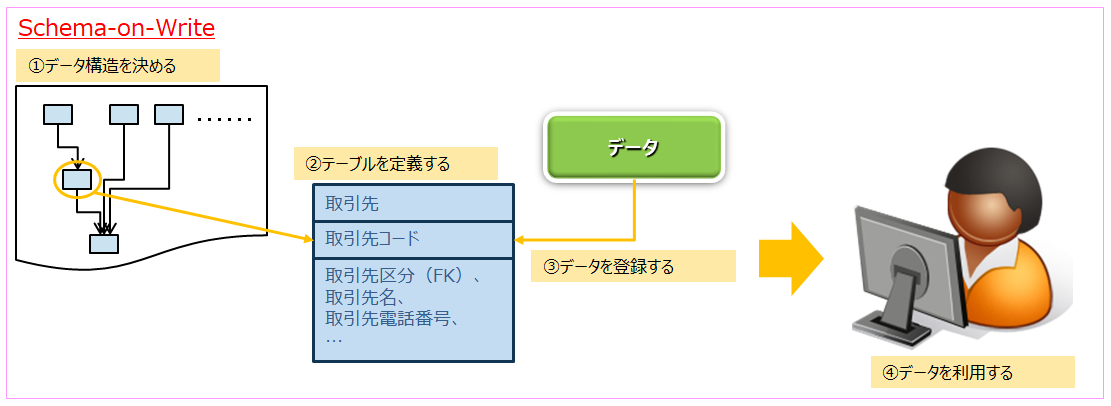
非構造化データとは?
次に非構造化データ(Unstructured Data)の特徴を挙げてみます。
非構造化データの特徴はビッグデータの特徴を表す「3V」に表れています。
ビッグデータの特徴を表す「3V」
- Volume(量が多い)
- Velocity(発生・更新頻度が高い)
- Variety(データや発生場所の種類が多い)
非構造化データの形式や内容には決まりがなく、インターネットなどを利用して集められるあらゆるデータを含みます。
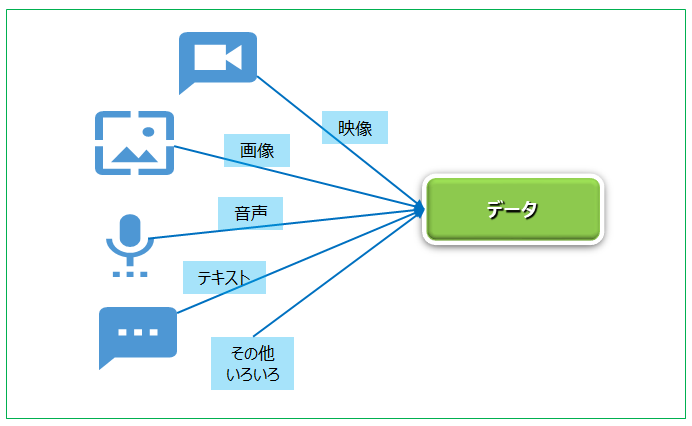
非構造化データの量は急激に増加し続けており、それらを集めることも容易になってきています。ただし、非構造化データをただ集めるだけでは使うことはできません。集めた非構造化データの信頼性を担保し、内容を把握し、使える形に変換する、つまり『半構造化する』必要があります。
半構造化データとは?
半構造化データ(Semi-Structured Data)は非構造化データに「フレキシブルな構造」を与えたものと定義されます。「フレキシブルな構造」は「NoSQL」とも呼ばれ、グラフ型・キーバリュー型・ドキュメント型・カラム型の4つに分類され、いずれもデータ+名前(タグ)の組み合わせでデータを管理します。
非構造化データに「フレキシブルな構造」を与えた結果である半構造化データは、構造化データと対称的な特徴を持ちます。集めたデータに合わせて名前(タグ)をつけて保存し、そのデータを利用したいときに利用したい形のデータ構造に当てはめる、Schema-on-Readの方式を取ります。それにより、非構造化データの特徴でもある多種多様なデータを取り扱うことができ、NoSQLデータベースで実装されます。
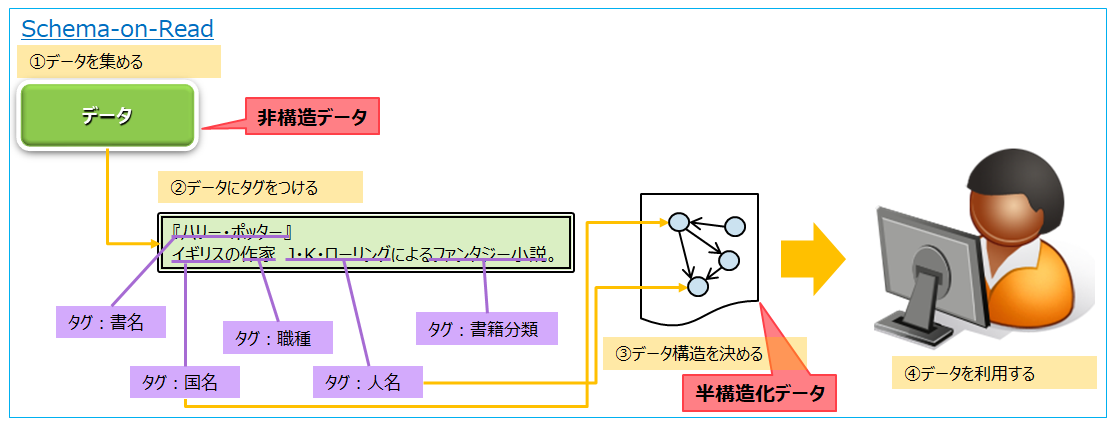
いま非構造化データをどう活用するか、構造化データと非構造化データをどう組み合わせるか、に注目が集まっています。その注目の表れからか、最近では、先述した「ビッグデータの特徴を表す3V」に「4つ目の"V":Value(価値)」と「5つ目の"V":Veracity(正確さ・信頼性)」が加わりました。
※4つ目の"V"と5つ目の"V"は明確に定まったものではなく所説あります。
急増する非構造化データを集めることは容易ですが、それだけでは価値を生むことはできません。
非構造化データからValue(価値)を得るためには、まず非構造化データの特徴や取り扱い方法を理解し、構造化データと同様に、非構造化データや半構造化データも適切に管理していく必要があります。
半構造化データの参考情報
ブログ「マクロとミクロ:2つのレベルで半構造化データを定義する」
半構造化データの定義方法について、解説しています。
https://jp.drinet.co.jp/blog/datamanagement/qcfixpdzmf
ブログ「半構造化データのマクロレベルとミクロレベルの関連と注意点の考察 ~非構造化データの意味を定義する~」
非構造化データは、マクロとミクロの2つのグラフ構造で定義しますが、EDW(Enterprise Data World)でこれら2つのグラフ構造の関係がどう語られていたのかをお伝えします。




