.png)

はじめに ~概念・論理・物理データモデルの分け方~
こちらの記事『3分間でわかるデータマネジメント【データモデリング】』では、DMBOKにおける概念・論理・物理データモデルの違いを紹介しました。しかし、同記事でも書きましたが、実際のところ概念・論理・物理の考え方は人によってまちまちです。本記事では参考までに、データ総研で採用している、3層スキーマをもとにした概念・論理・物理データモデルの分け方を紹介いたします。
また、データ総研では概念データモデルを描く際、詳細度に応じて3種類の記載法を使い分けています。それぞれについて、概要や用途をご説明します。
概念データモデルの関連資料ダウンロード
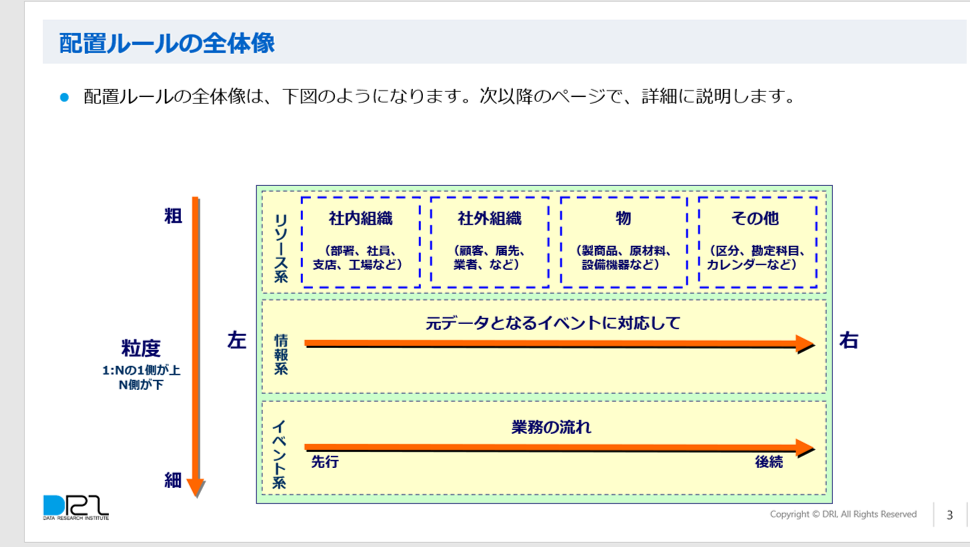
概念データモデルにおけるエンティティの適切な配置ルールを解説する資料をダウンロードいただけます。
こちらの配置ルールは、EDW(Enterprise Data World)というデータマネジメントの海外カンファレンスで発表された実績もあり、その中で高い評価を受けています。

1. 3層スキーマをもとにした概念・論理・物理データモデル
まず3層スキーマについて説明したのち、それをベースにした、データ総研における概念・論理・物理データモデルの分け方を紹介します。
3層スキーマアーキテクチャ

図1. 3層スキーマアーキテクチャのまとめ
1975年に、ANSI (米国国家規格協会、American National Standards Institute)が「3層スキーマアーキテクチャ」という考え方を提案しました。その中で、外部・概念・内部という三つのスキーマでデータを捉えることにより、より柔軟なシステム構築が可能であると述べています。ここでいう「スキーマ」とは、データの構造(どのようなデータがあるか、それらがどのような関係性をもつか…などのことです。
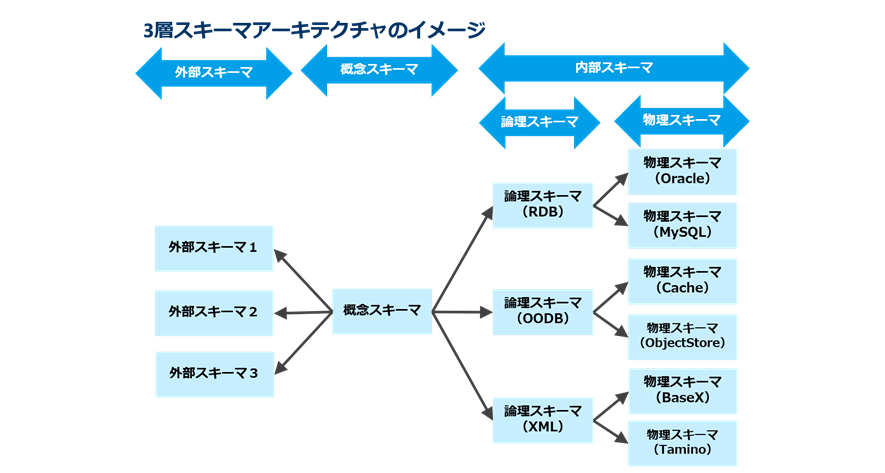
図2. 3層スキーマアーキテクチャのイメージ
外部スキーマは、ユーザーから見たデータの見え方を表しています。個々の画面・帳票をイメージするとわかりやすいです。外部スキーマでは、ユーザーの使用場面や目的によって、概念スキーマの中のデータのうち、見たい分のデータが見やすい形式で表示されます。
概念スキーマは、データベースに保持する必要があるデータ、およびデータ同士の関係性を表したものです。内部スキーマで決定されるデータの実装手段から独立して、データの意味の観点からデータ構造を表します。
内部スキーマは、概念スキーマのデータを、採用する技術や製品等に合わせてどのように実装するかを表したものです。内部スキーマはのちに、David Hayの Different Kinds of Data Models: History and a Suggestionにあるように、論理スキーマと物理スキーマに分けて考えられるようになりました。論理スキーマではDBMSの形式(リレーショナル、オブジェクト等)に合わせたデータ構造を表します。また、物理スキーマでは、採用するハードウェアやデータベース製品に合わせ、データを物理的に格納するためのデータ構造(パーティション、テーブル領域など)を表します。
概念・論理・物理データモデルと3層スキーマアーキテクチャの対応
データ総研の分類では、上記の概念スキーマ、(内部スキーマの中の)論理スキーマ、物理スキーマを表現するデータモデルをそれぞれ概念データモデル、論理データモデル、物理データモデルと呼んでいます。
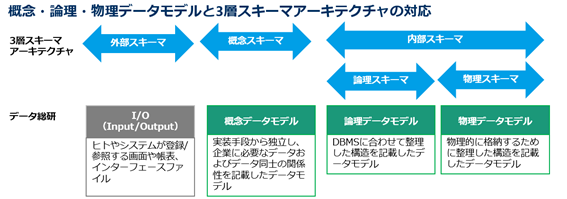
図3. 概念・論理・物理データモデルと3層スキーマの対応
まとめると、
・概念データモデル
実装手段から独立し、企業に必要なデータおよびデータ同士の関係性を記載したデータモデル
・論理データモデル
(概念データモデルのデータ構造を)DBMSに合わせて整理した構造を記載したデータモデル
・物理データモデル
(論理データモデルのデータ構造を)物理的に格納するために整理した構造を記載したデータモデル
ということになります。
ちなみに、外部スキーマについては、I/O(Input/Output、ヒトやシステムが登録/参照する画面や帳表、インターフェースファイル)が対応すると捉えています。
2. 「概念データモデル」は大きく分けて3レベル
データ総研の考え方でいえば、「実装独立」のモデルはすべて概念データモデルです。ただし、実務においては、状況に応じて概念データモデルの詳細度を使い分けたい場面が出てきます。
そこで、データ総研では、「概念データモデル」を以下の3つに分けています。
・鳥瞰データモデル…エンティティのみのモデル
・骨格データモデル…エンティティと主要属性が記載されたモデル
・詳細データモデル…すべてのデータ項目が記載されたモデル
データ総研では、これらの3種類のモデルを、用途に応じて使い分けています。
鳥瞰データモデル
図4. 鳥瞰データモデル図の例
鳥瞰データモデルには、主要なエンティティと、エンティティ間のリレーションシップのみを記載します。
鳥瞰データモデルを用いて、対象領域に「どのようなデータが存在するのか」「それぞれのデータ同士がどのような関係性なのか」を整理します。また、データを使用している業務領域や、データを格納しているアプリケーション、ハードウェアなどと鳥瞰データモデルをマッピングすることも多いです。
主に、システムの企画工程で作成されます。データベース設計に直接使うというよりは、関係者間の相互理解のために使います。鳥瞰データモデルがあれば、システム化のスコープに関して認識を合わせることが容易になります。また、鳥瞰データモデルを用いてデータとアプリケーションをマッピングし、それらの現状(AsIs)と将来像(ToBe)をそれぞれ描くことで、今後どのようにデータ統合を行っていくかの見通しが立てやすくなります。(これらの議論を行うには、のちに示す骨格・詳細データモデルの記載レベルは細かすぎます。)
そのほか、管理対象(およびそれに関するデータ)の呼び方を揃えることにも役立ちます。詳細データモデルを作成する際、複数の関係者間で同じ管理対象に対する呼び方が異なることがあり、しばしば混乱が生じます。その時、鳥瞰データモデルを用いて呼び方の認識を合わせるようにすると、スムーズな議論につながります。
骨格データモデル
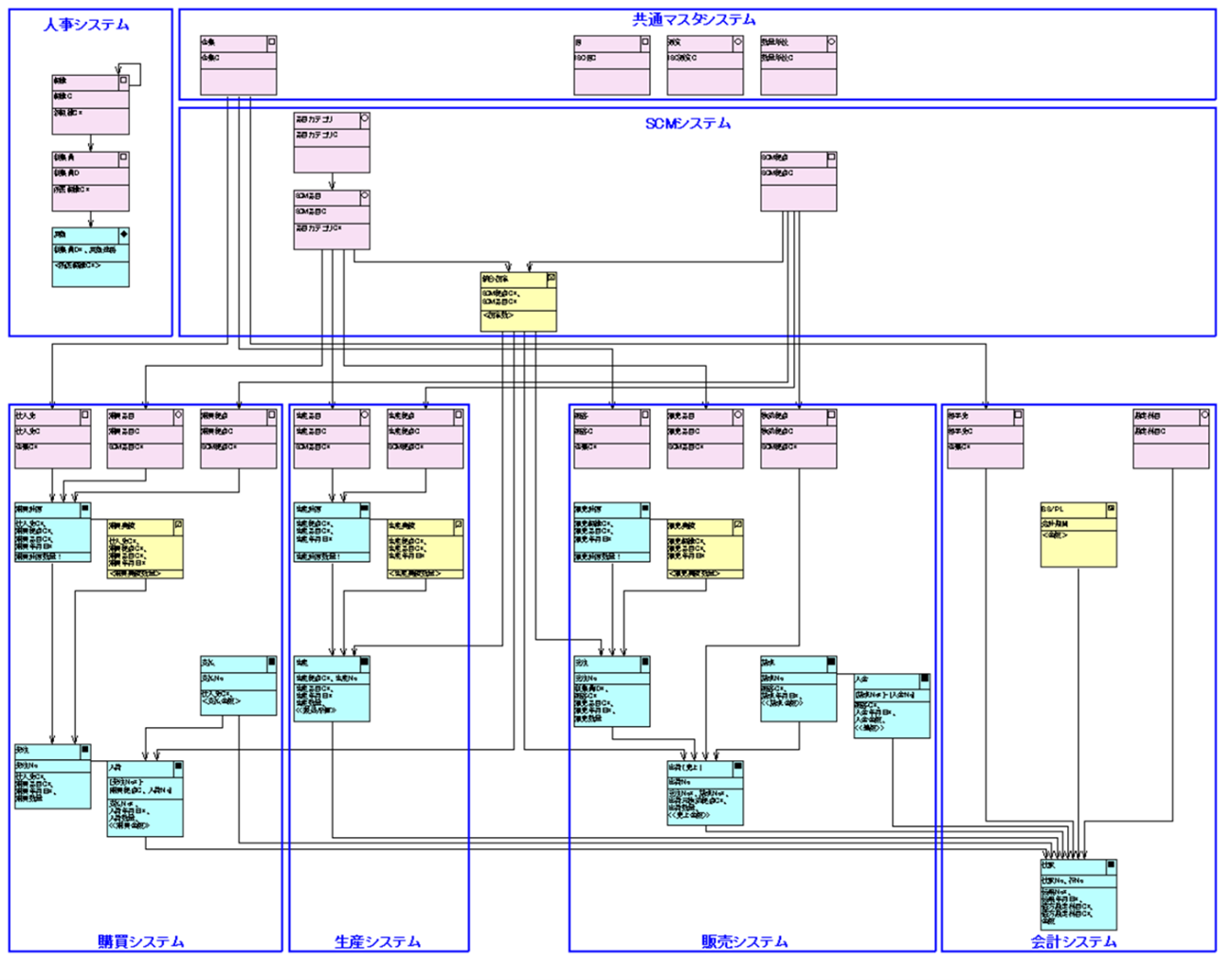
図5. 骨格データモデル図の例
骨格データモデルには、主要なエンティティと、それらのエンティティが保持している主要なデータ項目(主キー、参照キーなど)、エンティティ間のリレーションシップを記載します。
詳細データモデルを作成する前に、大枠のデータ構造や業務ルールを把握することを目的として作成することが多いです。
また、システム企画のために鳥瞰データモデルを描いたときに、実現性を確かめるための裏取りとして骨格データモデルを作成することもあります。
詳細データモデル

図6. 詳細データモデル図の例
詳細データモデルには、特定領域の業務におけるエンティティ、データ項目、エンティティ間のリレーションシップをすべて記載します。また、条件ごとに使われるデータ項目やその関係性が変わる場合(例:受注-出荷の業務のやり方が、扱う製品領域ごとで異なる)、サブタイプという表現方法を効果的に用いて、それらのバリエーションも記載します。
詳細データモデルは、データベース設計に直接つながるドキュメントです。詳細データモデルには、ユーザーのデータ要件がすべて記載されます。詳細データモデルをもとに、データベースの論理設計、物理設計が進んでいきます。
また、詳細データモデルを用いて既存業務のやり方をモデル化することで、既存業務の中で必要以上に複雑になっている部分を可視化することもできます。それをもとに、業務のシンプル化や標準化などに繋げることもできます。
さらに(忘れられがちなのですが)、詳細データモデルをしっかり描くことによって、データに必要な制約が表現されます。アプリケーションの開発では、必要な機能を実現することだけでなく、業務ルールに反した操作ができないようにすることも重要です。詳細データモデルは、操作に関する制約を正しく実装するためのインプットとしても役立ちます。
補足:DMBOK2の考え方との違い
なお、「はじめに」で書いたように、ここまでで紹介した考え方はDMBOK2における考え方とは違うものです。
参考までに、概念・論理・物理に関するデータ総研とDMBOK2の考え方の対応を表としてまとめておきます。
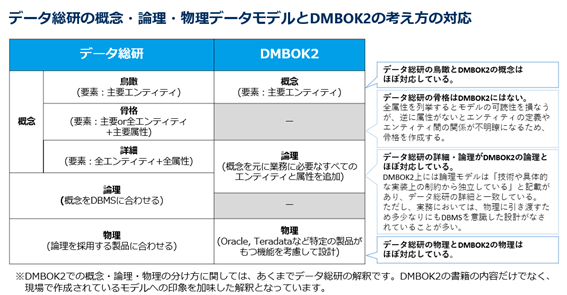
図7. データ総研とDMBOK2の考え方の対応
3. データモデルの名称に関する混乱への対処
ここまで、データ総研における概念・論理・物理データモデルの分け方や、概念データモデルの記載レベルについて書いてきました。このほかにも、データモデルの分け方には様々な意見があります。
同じ企業の中では呼び方に混乱が出ないように、それぞれの呼び方を定義するのがよいでしょう。
一方、他企業の方と話すときには、相手が今どんなデータモデルをイメージしているのか(実装独立かどうか、どのくらい詳細にデータ項目を記載するか……など)を適宜確認することが重要です。
おわりに ~概念データモデルの配置ルール~
データ総研では、概念データモデルの研修コースをご用意しています。研修の中では、鳥瞰、骨格、詳細の3レベルの概念データモデルの作成方法を学べます。概念データモデルをデータマネジメントに役立てようという方は、ぜひお申し込みください。
また、データ総研では、概念データモデルの配置ルールを提唱しています。データモデルの問題として、「エンティティが多くなった時に、読みづらくなってしまう」という問題があります。この問題にぶつかってしまい、「データモデルはコミュニケーションのツールとして役に立たない」と誤解してしまう人もいます。しかし実は、エンティティを適切に配置することによって、巨大なモデルになっても読みやすさを保つことができるのです。
こちらの配置ルールは、EDW(Enterprise Data World)というデータマネジメントの海外カンファレンスで発表された実績もあり、その中で高い評価を受けています。
鳥瞰、骨格、詳細データモデルすべてについて適用可能な配置ルールです。ぜひご参考にしてください。
データモデリングの参考情報
これがなければ始まらない!
データマネジメントの基本スキル「データモデリング」セミナー
本セミナーでは、まずデータマネジメントの全体像を紹介し、
なぜデータモデリングが基礎スキルなのかを解説します。
さらにデータモデルの種類とデータモデルが必要な場面について事例を交えて紹介し、
最後に当社の“実務で使えるデータモデリングの技法”が得られるデータモデリング教育コースの特徴とコース内容をご案内します。

概念データモデルの配置ルール

このホワイトペーパーでは、概念データモデルにおけるエンティティの適切な配置ルールをお伝えします。
モデルを作成するときに、モデル中のエンティティの量が増えると、どこに何のエンティティがあるのかわかりにくくなります。そうなると、データモデルを用いた議論やコミュニケーションが円滑に進みません。しかし、ここでご紹介する配置ルールがあれば、読みやすいモデルを作成することができます。
こちらの配置ルールは、EDW(Enterprise Data World)というデータマネジメントの海外カンファレンスで発表された実績もあり、その中で高い評価を受けています。
データアーキテクチャ設計に必須のデータモデリングスキルを習得

データアーキテクチャ設計に不可欠となるデータモデリングを初歩から学べる研修コース「データモデリング スタンダードコース 入門編」。これまで延べ15,000人以上もの方々がデータ総研のデータモデリング教育コースを受講しています。

データアーキテクト養成コース

データを活用するためにはデータマネジメントが欠かせないという認識が広まるにつれ、その推進役となるデータアーキテクトの必要性がますます高まっています。しかしながら、データマネジメントを体系的に理解し、実施すべき施策・活動を組織として実践できる人材はまだまだ限られています。
本コースでは、データマネジメントの全体像及び、実施すべき施策・活動を押さえたうえで、施策や活動の目的や位置付けと、そのために必要な観点や基本フレームを中心に学習していきます。随所で小演習をはさみながら、具体的課題への対応方法を体験していただき、データアーキテクトとして活躍できる人材の育成を図ります。
データアーキテクトとなる当事者だけでなく、組織・顧客にデータマネジメントの推進を促す立場の方、データマネジメントの全体像を把握したいSEの方などにも必修の内容です。