.png)

データモデリングの意味、必要とされる理由、進め方を解説
本記事では、ユーザー企業の方向けにデータモデリングについて解説していきます。
データモデリングは、データに関する要件を明確化するための技術です。この技術は、データマネジメントを成功させるうえで必須のものとなっています。(”そもそも「データマネジメント」とは?” という方は、こちらの記事『データマネジメントとは何か』もご覧ください。)
本記事ではデータモデリング(およびその成果物であるデータモデル)について、そもそもの意味や必要とされる理由、進め方等について解説いたします。
3分でわかるデータマネジメント【データモデリング】の想定読者層
本記事は、以下の方々を想定して作成しております。
- 情報システム構築やパッケージ導入に携わる方(特に、ユーザー企業の情報システム部門の方)
- デジタルトランスフォーメーションに携わる上で、データから価値を見出したいと考えている方
データモデリングとは?
データモデリングについて、DMBOK2では、次のように書かれています。
データモデリングとは、データ要件を洗い出し、分析し、取扱スコープを定めるプロセスであり、データ要件を記述し伝えるために、明確に定義されたデータモデルと呼ばれる様式が用いられる。このプロセスは反復的であり、概念、論理、物理モデルが含まれる。
--『データマネジメント知識体系ガイド 第二版』DAMA International編著、DAMA日本支部・Metafindコンサルティング株式会社訳、日経BP社、2018
要するにデータモデリングとは、データに関する要件の明確化や、実装範囲の決定を目的に、データモデルを作成することです。
ここでいうデータモデルとは、あらかじめ定めた様式に従ってデータの名称や定義、データ同士の関係性などを記述したものです。データモデルの主要な構成要素として、次が挙げられます。
- データモデル図
- データモデル図に書かれたエンティティ・属性の詳細な定義や、値の入り方のルール
データモデリングを行って明確になったデータの名称や定義、値の入り方のルール、データモデル図などは、メタデータとして管理され、様々な場面で使用されることになります。
(メタデータについてはこちら→『3分でわかるデータマネジメント【メタデータ管理】』)
データモデル図については、後半で説明します。
なぜデータモデリングに取り組む必要があるのか?
ここでは、ユーザー企業がデータモデリングに取り組むべき理由を紹介します。
1.企業・組織にどのようなデータがあるか把握するため
企業活動では、多くのデータを利用します。今社内にどのようなデータがあり、それらが何を表しており、データ間でどのような関係性をもっているのか……それらを人間の頭の中だけで記憶し、管理するのはとても難しいです。そこで、企業や組織の中にあるデータを、ドキュメントに残し、分からないことがあったときに参照できるようにしておく必要があります。
そこでデータモデリングによって、企業・組織に存在するデータを可視化します。データモデリングでデータの意味や関係性を把握することは、データを活用して経営判断に繋げようとする企業にとって、最も基礎的な取り組みと言えます。そもそもどんなデータがあるのか知らなければ、活用することもできないためです。もちろん、データに関わるリスク(個人情報の流出など)を防止しようとする際にも、同じことが言えます。
2.データアーキテクチャを設計し、今後データに関して取り組むべきことを決めるため
データモデリングは、データアーキテクチャ設計のために必要不可欠です。データアーキテクチャとは、かんたんに言うと「将来的に、どういったデータをどのように取得・保持・活用するかの青写真」です(→『3分間でわかるデータマネジメント【データアーキテクチャ】』)。データアーキテクチャは、各種のデータマネジメントやデータガバナンスを全体最適の形で行うために必須です。
全体視点で見たときの「データのあるべき姿」を設計しておくことで、データに関わる様々なプロジェクトの連携を取ることができます。例えば、MDMシステムの開発や、DWHの構築などの際には、「どのデータをどこから集めてくるか」「粒度や、保有するデータ項目、型桁などをどう揃えるか」が必ず問題になります。データアーキテクチャ(とそれを構成するデータモデル)は、それらを判断するために必要になってきます。もし企業としてのデータアーキテクチャが無い場合、各部門が好き勝手にデータ統合を行ってしまい、かえってデータが散在するようになるかもしれません。
3.データ要件をシステム開発者に正しく伝えるため/システム保守を効率よく行うため
システムは、つまるところ「業務で必要なデータを適切に出し入れするための装置」といえます。すなわち、システムを開発するには、そのシステムでどんなデータが扱われるかわかっていなければいけません。そして、そのシステムで扱われるべきデータの名称や意味など、形式などを正しく定義できるのは、(開発会社ではなく)ユーザー企業の方です。
そこで、データに関する要件を定義し伝えるために、ユーザー企業側でデータモデルを作成します(多くの場合、要件定義工程で行われます)。作成したデータモデルを開発者に渡すことによって、言葉だけでは伝えることが難しい、データ同士の関係性を伝えることができるようになります。それにより、必要なデータがヌケモレなく扱われているような、高品質なシステムを開発することができます。
また、システムを効率よく保守するためにも、データモデルは有効です。システムで扱われているデータのデータモデルがあることで、保守を行う際にデータの意味や、データどうしの関係性を特定しやすくなります。その結果、加えた変更の影響や影響範囲が特定しやすくなり、保守にかかる時間を短縮することができます。
データモデル図とは
データの名称とデータ同士の関係性をビジュアライズした図面を、データモデル図と言います。以下、データモデル図を構成する要素について簡単に解説します。

図1. データモデル図およびその構成要素の例
データモデル図は主に、エンティティ、属性、リレーションシップから構成されます(図1)。
組織が情報を収集する対象のことを、エンティティといいます。たとえば、自社の「商品」や「社員」、取引をする「顧客」、発生した「受注」などがエンティティとなります。長方形の箱で表されることが多く、その中にエンティティ名や属性を記述します。
エンティティごとに管理される要素のことを、属性といいます。属性のことを「データ項目」とも言います。たとえば、顧客というエンティティで管理される属性には、「顧客名」「顧客住所」などがあります。
エンティティ間に関係性があることを表すのが、リレーションシップです。詳しい説明は割愛しますが、図1の例ではリレーションシップを矢線(“↓”)で表しています。
データモデル図の書き方には多くの記法があります。ちなみに図1の記法は、データ総研でデータモデル図を描くときに使っているTH記法です。その他、有名な記法としてIE記法やIDEF1xなどがあります。
データモデルの種類
データモデルは概念データモデル、論理データモデル、物理データモデルの3種類に分けられます。これらは、使用用途に応じて使い分けられます。参考までにDMBOK2での分け方についてご紹介します。
・概念データモデル
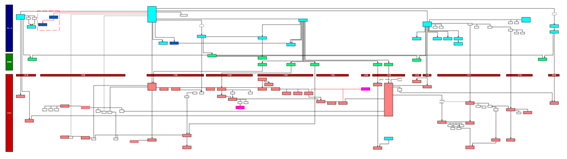
図2. 概念データモデル図の例(エンティティ名は省略してある)
基本的&重要なエンティティのみを対象にしたデータモデルです。これらのデータをどのように実装するかは考慮せずに、企業の現実をそのまま写し取るようにモデル化します(実装独立)。図2は、全社レベルの概念データモデルを作成した例です。企業にとって重要なエンティティを抽出し、ルールに基づいて配置を行っています。
・論理データモデル
概念データモデルよりもデータの要件が詳細に書かれたデータモデルです。概念データモデルに属性を追加し、正規化という作業を行って作られます。概念データモデルと同じく、実装手段は考慮しません。アプリケーション単位など、モデル化の対象になるデータを絞ったうえでモデリングするのが普通です。
・物理データモデル
採用するデータベース製品を想定して、データをどのように実装するかを詳細に表したモデルです。多くの場合、論理データモデルをもとに作成されます。
以上、DMBOK2での概念・論理・物理の分け方をご紹介しました。ただし、実際のところ概念・論理・物理の考え方は人によってまちまちです。単に「概念データモデル」と言ったときにそこにいる全員が同じものを想像するとはかぎりません。データモデルの話をする時は、モデル化の範囲や詳細度、実装独立か否かなどの条件をきちんと確認したほうが良いでしょう。
データモデリングの進め方
多くの場合、データモデリングは次のように進んでいきます。
1.データモデリングの計画立案
まず、その組織でデータモデリングを行う目的を明らかにします。多くの場合、データモデリングの活動は理解が得にくく、作成者のモチベーションが上がらない・業務部門からの協力が得られないなどの事態が起こります。データモデリングの目的をはっきりさせることは、そのような事態を防ぐことに繋がります。
目的が明らかになったところで、データモデルを作成するスコープや、必要なデータモデルの種類、作成にかける期間などを決めていきます。
また、データモデル構築の前に、成果物の形式を事前に定めておきます。事前に成果物の形式を定めておかないと担当者間で形式が成果物の質がばらついてしまいます。それを防ぐためにも、事前にひな形や、モデル図の表記ルール、エンティティや属性の命名規則、定義に含まれるべき内容などを決めておきます。
2.データモデルの作成
事前に定めた形式に従って、データモデルを作成します。データモデルを作成するために必要な資料を収集したり担当者にヒアリングを行ったりして、モデルを作成していきます。
モデルを作成していると、ほとんどの場合、業務のプロセスや用語の意味などについて疑問が出てきます。その際、それらに詳しい人(業務部門の担当者など)にヒアリングしながら進めていきます。
3.作成したデータモデルのレビュー
データモデルの品質を担保するために、作成したデータモデルをレビューします。内容の誤り、形式に沿っていない部分など、問題がないかチェックします。問題がなければ承認し、問題があった場合には作成者に対して改善を依頼します。
4.データモデルの更新
データに関する要件が変わった場合、その都度データモデルを更新します。
おわりに ~データモデリングの習得~
データモデリングは、今後ユーザー企業にとっても必須のスキルになってくるでしょう。しかし、ユーザー企業の方からすると「データモデリングを行う機会がなく、習得が難しい」というのが正直なところではないでしょうか。
弊社では、データモデリングを身に付けるための研修を行っています。実際のモデリング業務にかなり近いような形で、無理なく学習することができます。詳細・お申し込みは以下をご確認ください。
データモデリングの参考情報
これがなければ始まらない!
データマネジメントの基本スキル「データモデリング」セミナー
本セミナーでは、まずデータマネジメントの全体像を紹介し、
なぜデータモデリングが基礎スキルなのかを解説します。
さらにデータモデルの種類とデータモデルが必要な場面について事例を交えて紹介し、
最後に当社の“実務で使えるデータモデリングの技法”が得られるデータモデリング教育コースの特徴とコース内容をご案内します。

15,000人以上の受講実績!
データマネジメントに欠かせないコアスキル
「データモデリング」を学べます!

データモデリング初心者が学ぶべき全ての知識を効率的に習得!実務に近い感覚で概念データモデリングの演習を行えます。研修期間中は、マンツーマンによる2回のオンライン講習と、3つの学習課題に取り組んでいただきます。





